What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Please see the paper and blog post for more information (links below).
Paper: link
Blog Post: link
Video Summary
Overview
- In this paper, we conduct an extensive study of six offline learning algorithms for robot manipulation on five simulated and three real-world multi-stage manipulation tasks of varying complexity, and with datasets of varying quality.
- Our study analyzes the most critical challenges when learning from offline human data for manipulation.
- Based on the study, we derive a series of lessons to guide future work, and also highlight opportunities in learning from human datasets, such as the ability to learn proficient policies on challenging, multi-stage tasks and easily scale to natural, real-world manipulation scenarios.
- We have open-sourced our datasets and all algorithm implementations to facilitate future research and fair comparisons in learning from human demonstration data.
Why is learning from human-labeled datasets difficult?
We explore five challenges in learning from human-labeled datasets.
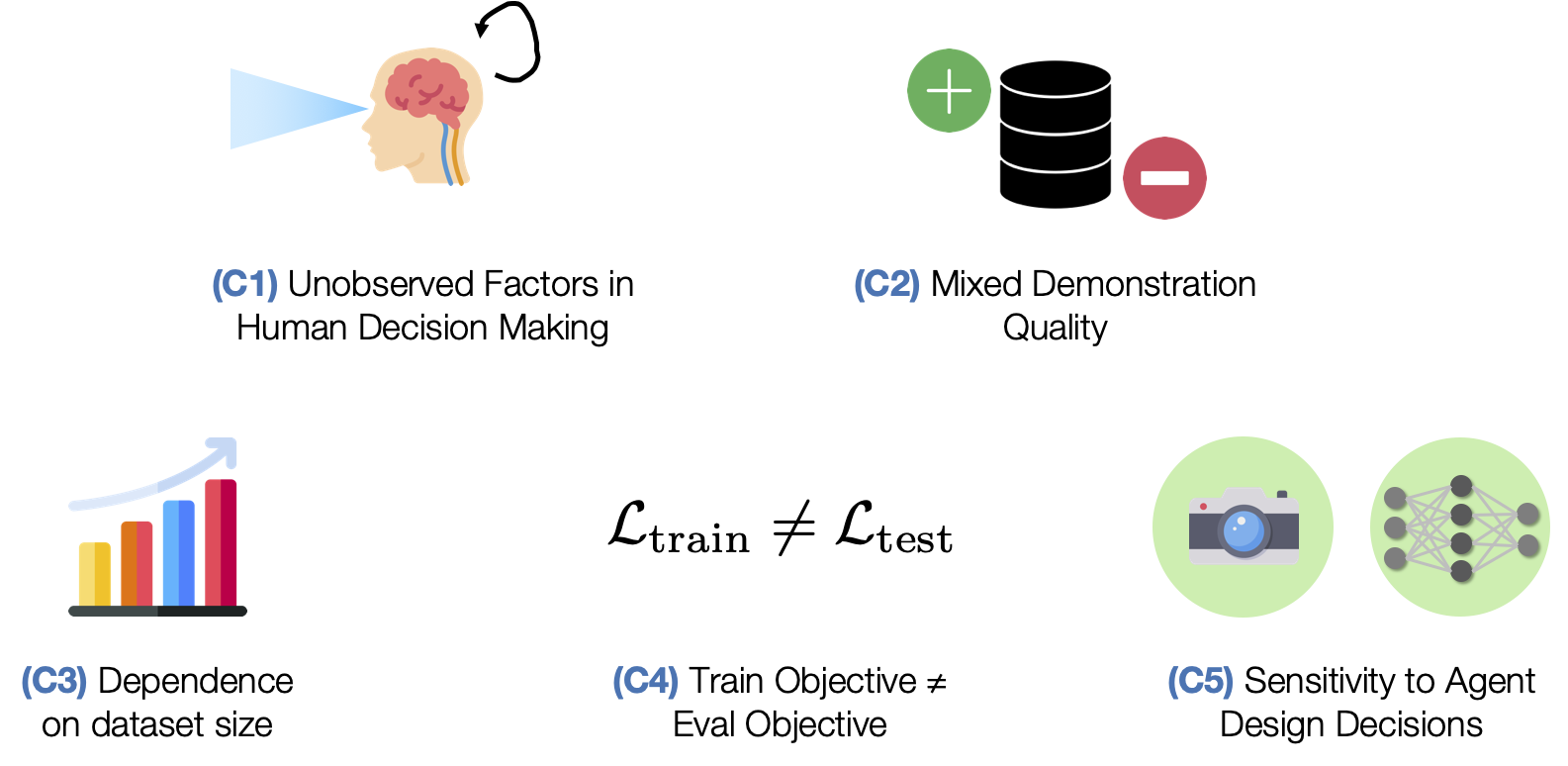
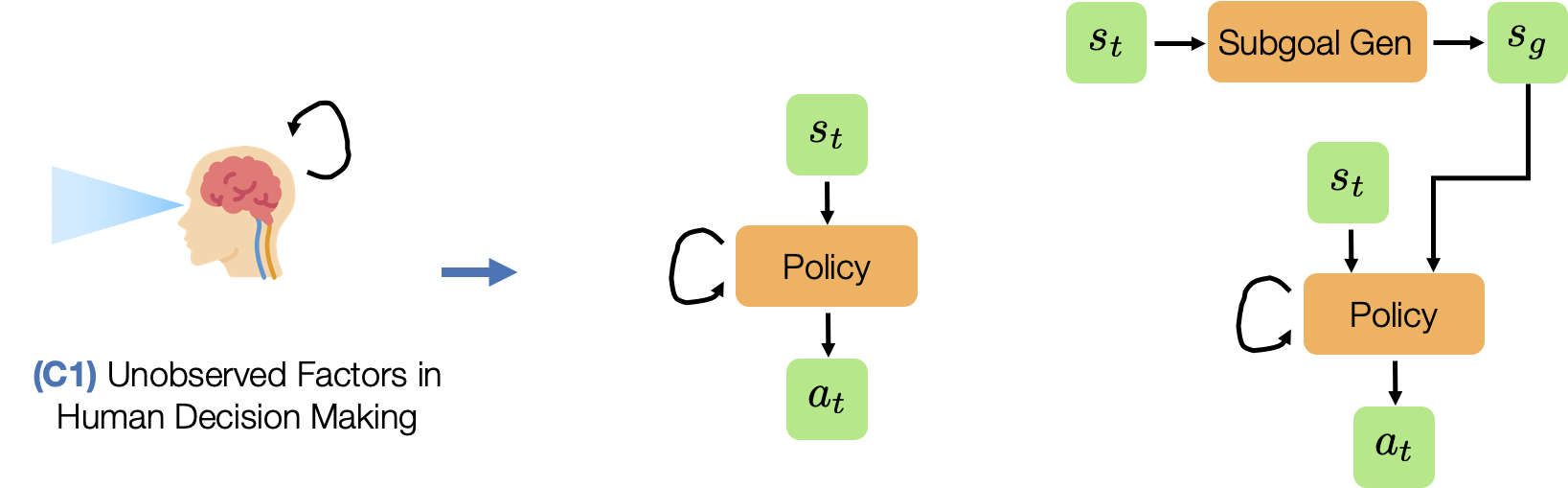
- (C1) Unobserved Factors in Human Decision Making. Humans are not perfect Markovian agents. In addition to what they currently see, their actions may be influenced by other external factors - such as the device they are using to control the robot and the history of the actions that they have provided.
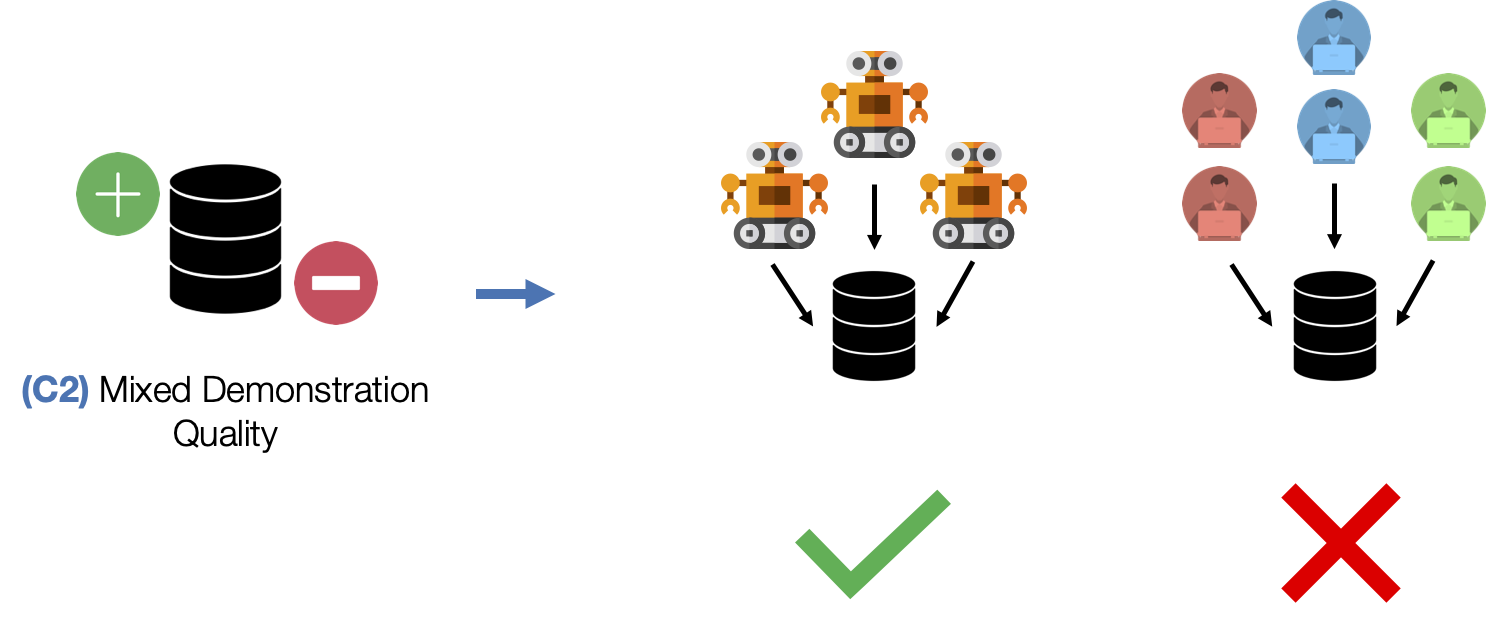
- (C2) Mixed Demonstration Quality. Collecting data from multiple humans can result in mixed quality data, since some people might be better quality supervisors than others.
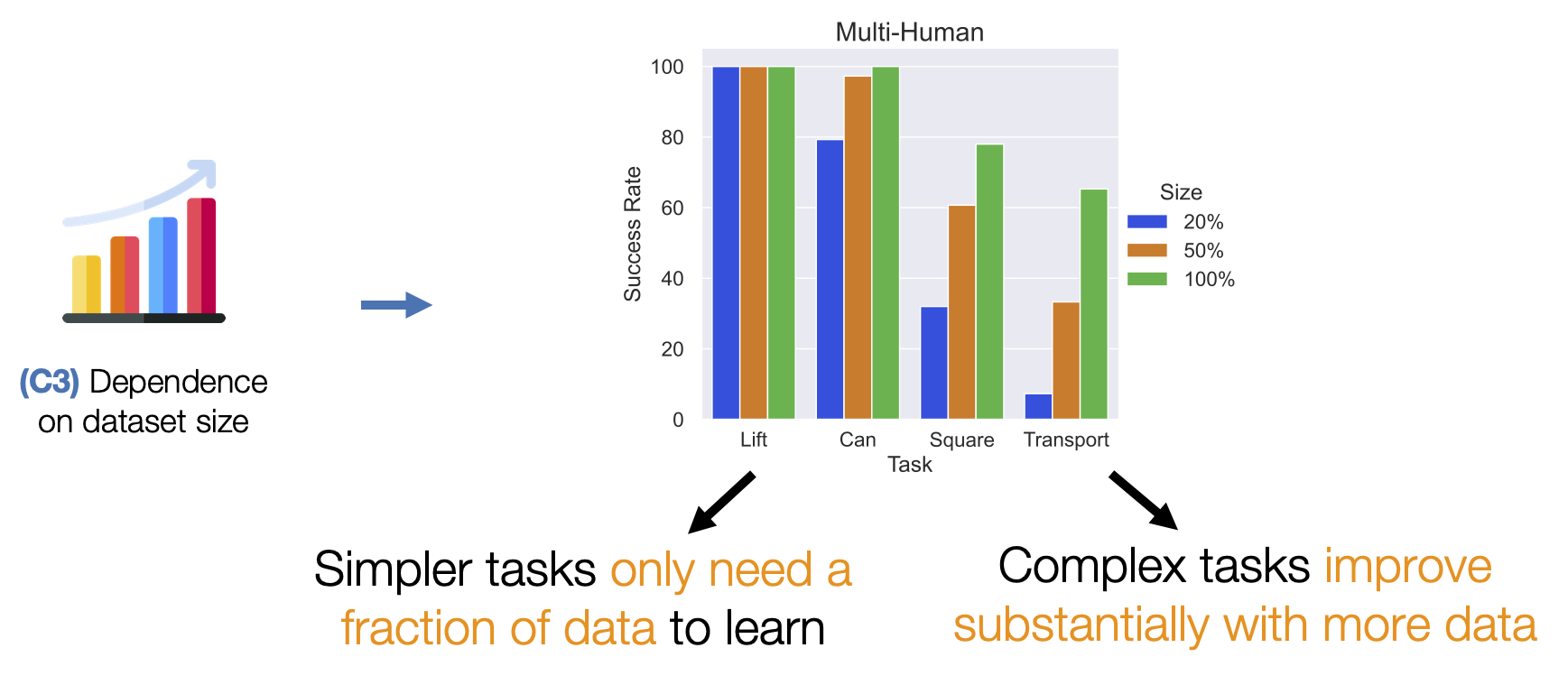
- (C3) Dependence on dataset size. Policy learning is also sensitive to the state and action space coverage in the dataset.
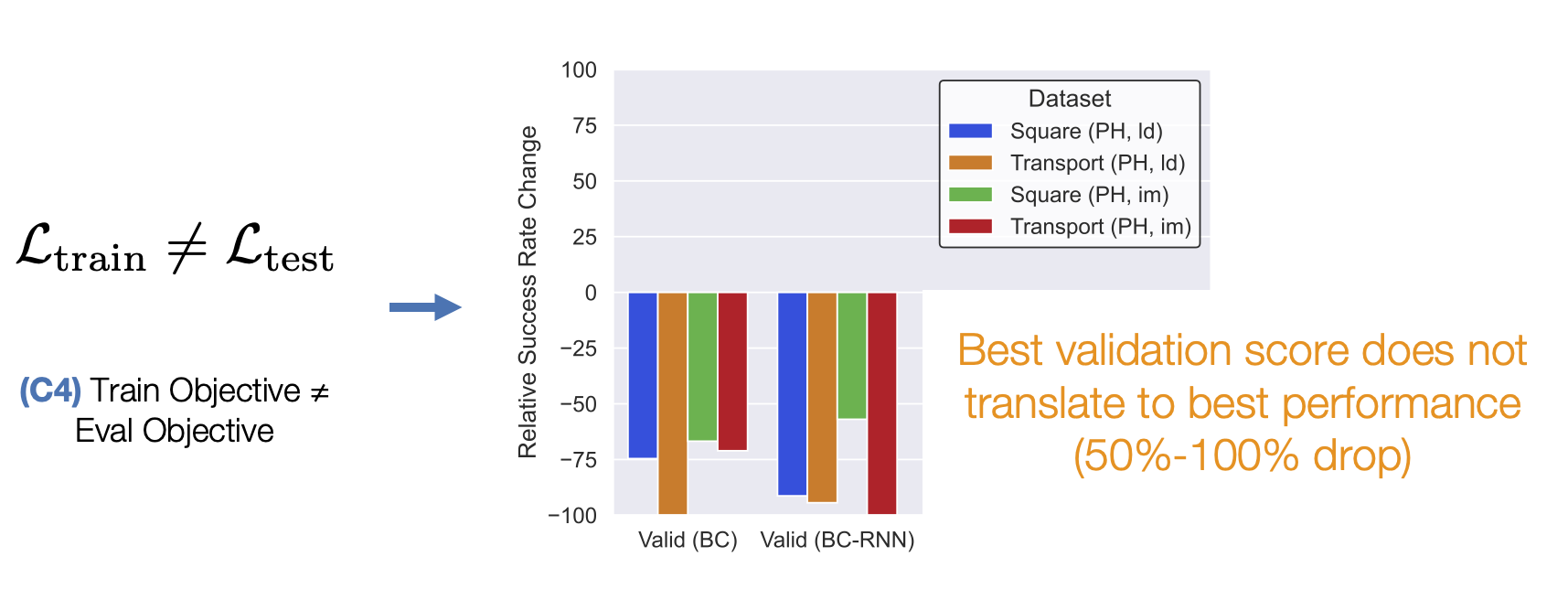
- (C4) Train Objective ≠ Eval Objective. Unlike traditional supervised learning, where validation loss is a strong indicator of how good a model is, policies are usually trained with surrogate losses. This makes it hard to know which trained policy checkpoints are good without trying out each and every model directly on the robot – a time consuming process.
- (C5) Sensitivity to Agent Design Decisions. Performance can be very sensitive to important agent design decisions, like the observation space and hyperparameters used for learning.
Next, we summarize the tasks (5 simulation and 3 real), datasets (3 different variants), algorithms (6 offline methods, including 3 imitation and 3 batch reinforcement), and observation spaces (2 main variants) that we explored in our study.
Study Design: Tasks
Study Design: Task Reset Distributions







Study Design: Datasets
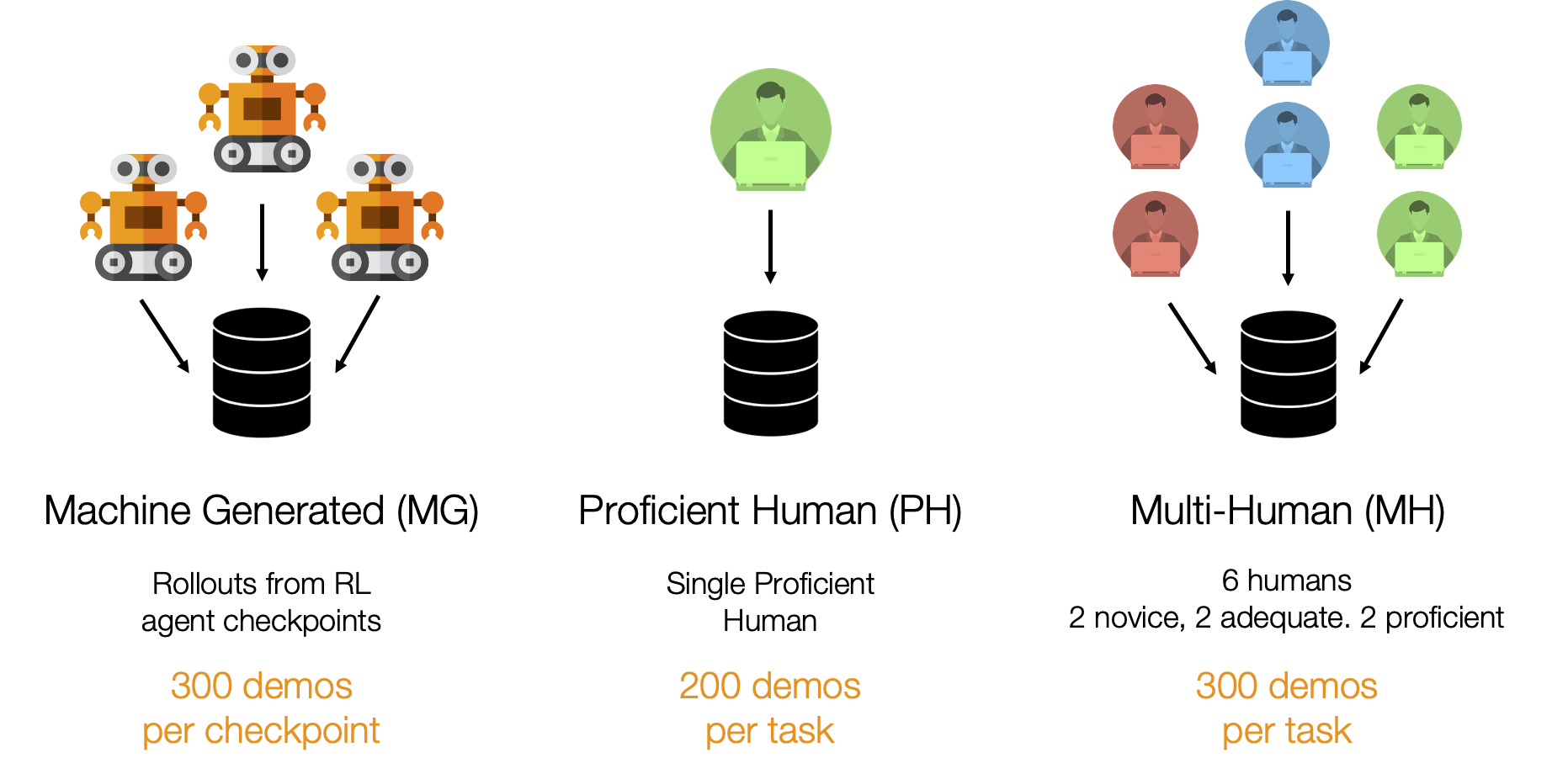
Machine-Generated
These datasets consist of rollouts from a series of SAC agent checkpoints trained on Lift and Can. As a result, they contain random, suboptimal, and expert data. This kind of mixed quality data is common in offline RL works (e.g. D4RL, RLUnplugged).
Proficient-Human
These datasets consist of 200 demonstrations collected from a single proficient human operator using RoboTurk.
Multi-Human
These datasets consist of 300 demonstrations collected from six human operators of varied proficiency using RoboTurk. Each operator falls into one of 3 groups - “Worse”, “Okay”, and “Better” – each group contains two operators. Each operator collected 50 demonstrations per task. As a result, these datasets contain mixed quality human demonstration data. We show videos for a single operator from each group.
Study Design: Algorithms
We evaluated 6 different offline learning algorithms in this study, including 3 imitation learning and 3 batch (offline) reinforcement learning algorithms.
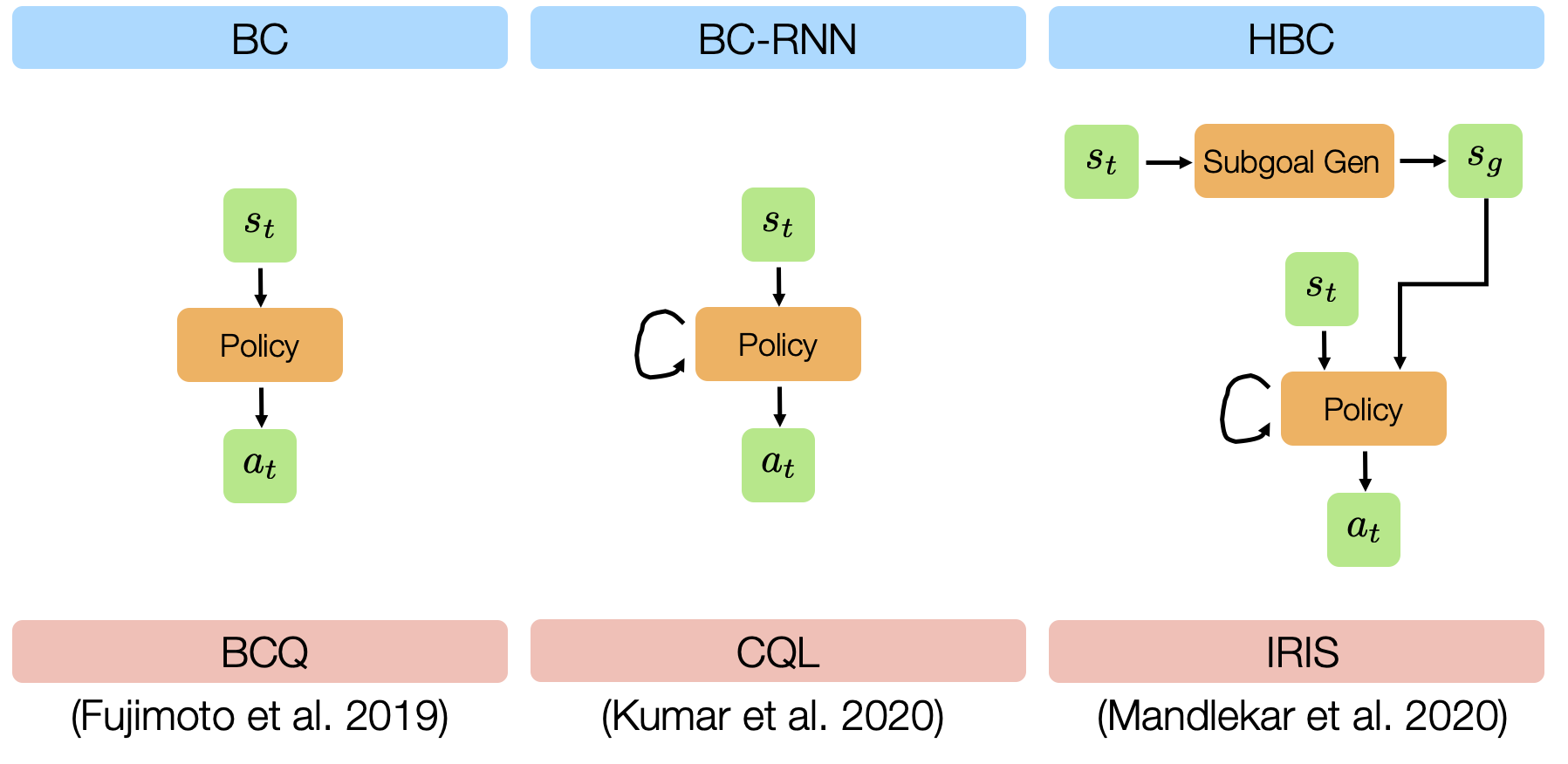
- BC: standard Behavioral Cloning, which is direct regression from observations to actions.
- BC-RNN: Behavioral Cloning with a policy network that’s a Recurrent Neural Network (RNN), which allows modeling temporal correlations in decision-making.
- HBC: Hierarchical Behavioral Cloning, where a high-level subgoal planner is trained to predict future observations, and a low-level recurrent policy is conditioned on a future observation (subgoal) to predict action sequences (see this paper and this paper for more details).
- BCQ: Batch-Constrained Q-Learning, a batch reinforcement learning method proposed in this paper.
- CQL: Conservative Q-Learning, a batch reinforcement learning method proposed in this paper.
- IRIS: Implicit Reinforcement without Interaction, a batch reinforcement learning method proposed in this paper.
Study Design: Observation Spaces
We study two different observation spaces in this work – low-dimensional observations and image observations.
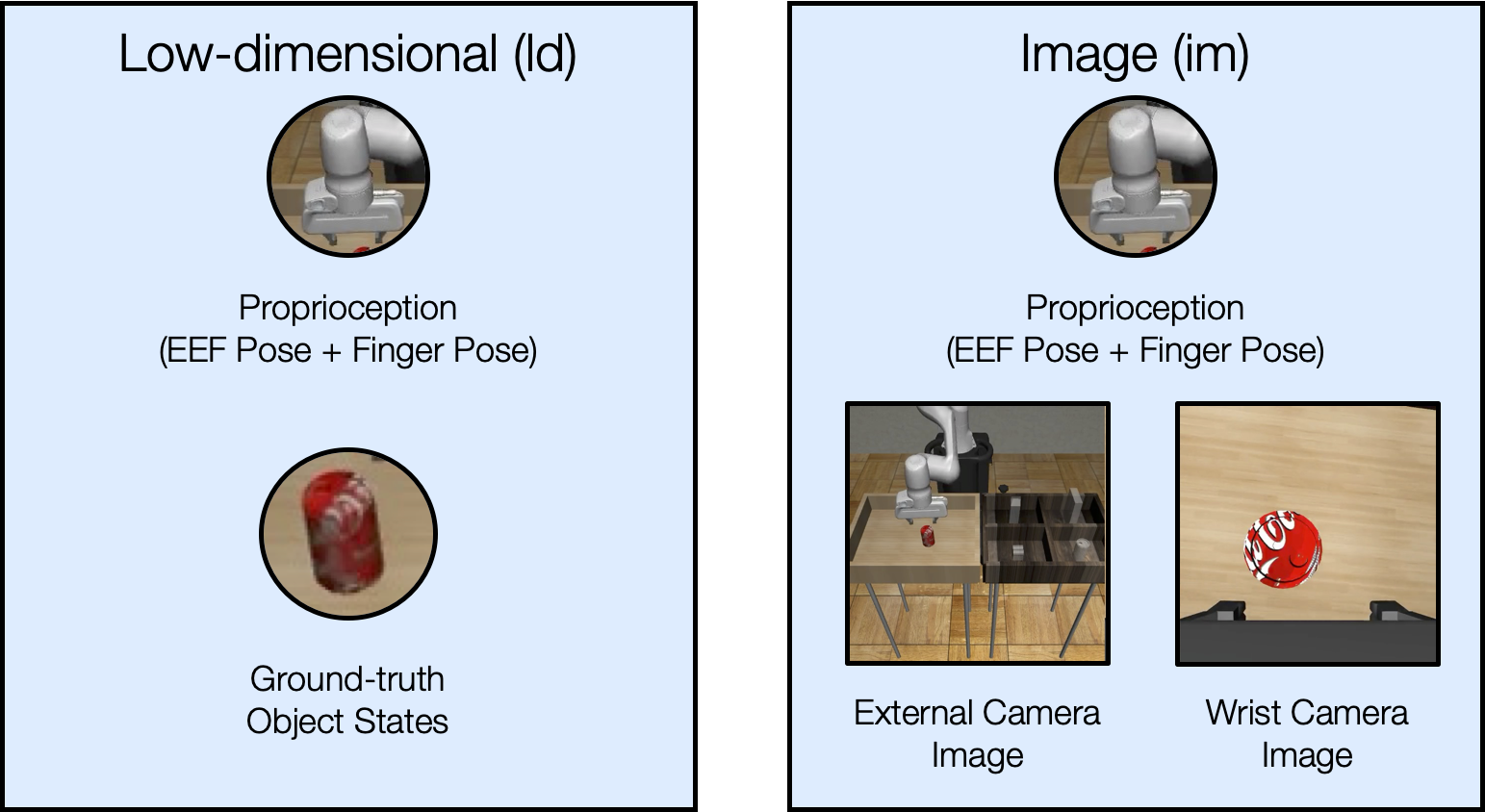
Image Observations
We provide examples of the image observations used in each task below.
Summary of Lessons Learned
In this section, we briefly highlight the lessons we learned from our study. See the paper for more thorough results and discussion.
Lesson 1: History-Dependent Models are extremely effective.
Lesson 2: Batch Offline RL struggles with suboptimal human data.
Lesson 3: Improving Offline Policy Selection is important.
Lesson 4: Observation Space and Hyperparameters play a large role in policy performance.

Lesson 5: Using Human Data for manipulation is promising.
Lesson 6: Study Results transfer to Real World.
We collected 200 demonstrations per task, and trained a BC-RNN policy using identical hyperparameters to simulation, with no hyperparameter tuning. We see that in most cases, performance and insights on what works in simulation transfer well to the real world.
Below, we present examples of policy failures on the Tool Hang task, which illustrate its difficulty, and the large room for improvement.
We also show that results from our observation space study hold true in the real world – visuomotor policies benefit strongly from wrist observations and pixel shift randomization.
Takeaways

- Learning from large multi-human datasets can be challenging.
- Large multi-human datasets hold promise for endowing robots with dexterous manipulation capabilities.
- Studying this setting in simulation can enable reproducible evaluation and insights can transfer to real world.
Additional Policy Evaluation Videos
In this section, we provide some additional policy rollout videos.